Terms
Why Would You Use Terms on Datasets?
The Business Glossary(Term) feature in DataHub helps you use a shared vocabulary within the orgarnization, by providing a framework for defining a standardized set of data concepts and then associating them with the physical assets that exist within your data ecosystem.
For more information about terms, refer to About DataHub Business Glossary.
Goal Of This Guide
This guide will show you how to
- Create: create a term.
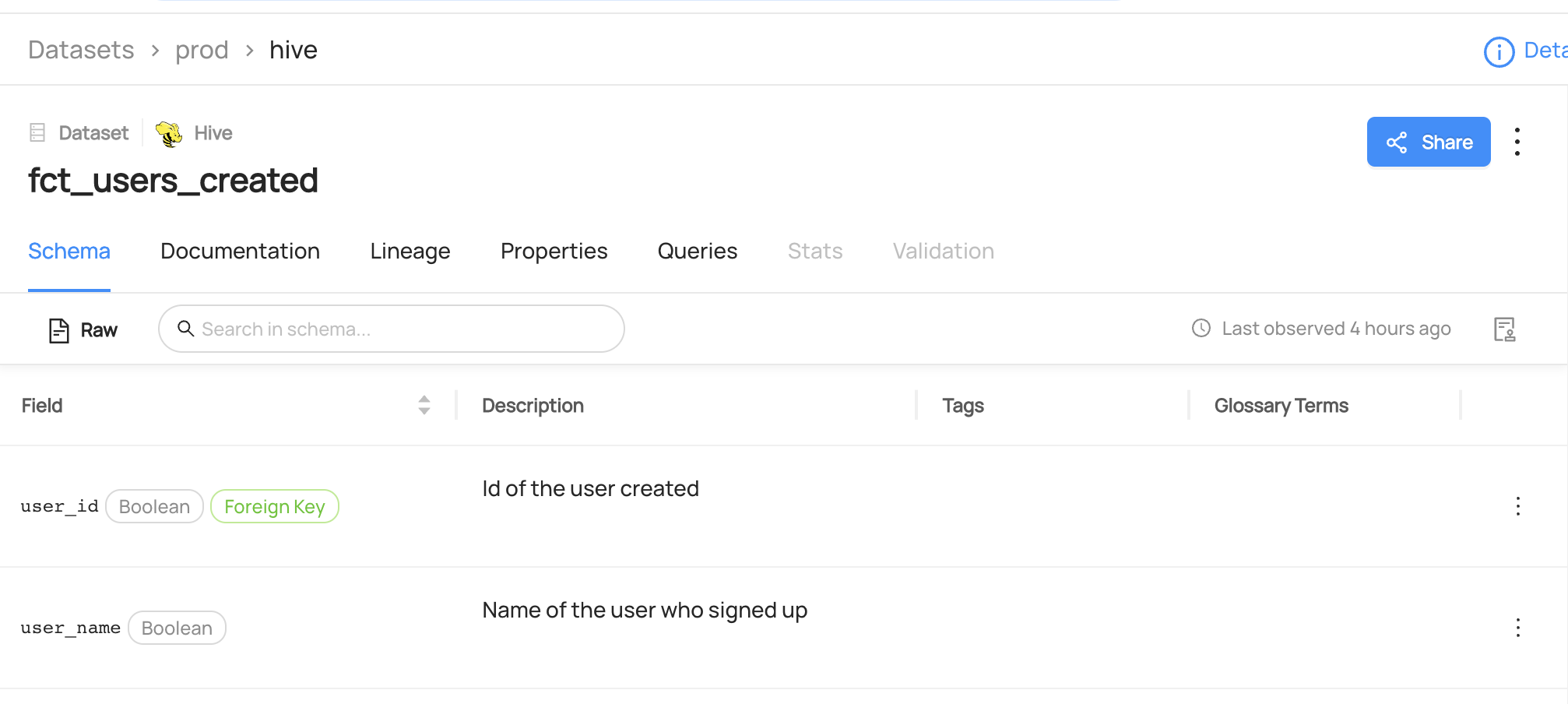
- Read : read terms attached to a dataset.
- Add: add a term to a column of a dataset or a dataset itself.
- Remove: remove a term from a dataset.
Prerequisites
For this tutorial, you need to deploy DataHub Quickstart and ingest sample data. For detailed information, please refer to Datahub Quickstart Guide.
Before modifying terms, you need to ensure the target dataset is already present in your DataHub instance. If you attempt to manipulate entities that do not exist, your operation will fail. In this guide, we will be using data from sample ingestion.
For more information on how to set up for GraphQL, please refer to How To Set Up GraphQL.
Create Terms
The following code creates a term Rate of Return.
- GraphQL
- Curl
- Python
mutation createGlossaryTerm {
createGlossaryTerm(input: {
name: "Rate of Return",
id: "rateofreturn",
description: "A rate of return (RoR) is the net gain or loss of an investment over a specified time period."
},
)
}
If you see the following response, the operation was successful:
{
"data": {
"createGlossaryTerm": "urn:li:glossaryTerm:rateofreturn"
},
"extensions": {}
}
curl --location --request POST 'http://localhost:8080/api/graphql' \
--header 'Authorization: Bearer <my-access-token>' \
--header 'Content-Type: application/json' \
--data-raw '{ "query": "mutation createGlossaryTerm { createGlossaryTerm(input: { name: \"Rate of Return\", id:\"rateofreturn\", description: \"A rate of return (RoR) is the net gain or loss of an investment over a specified time period.\" }) }", "variables":{}}'
Expected Response:
{
"data": { "createGlossaryTerm": "urn:li:glossaryTerm:rateofreturn" },
"extensions": {}
}
# Inlined from /metadata-ingestion/examples/library/create_term.py
import logging
from datahub.emitter.mce_builder import make_term_urn
from datahub.emitter.mcp import MetadataChangeProposalWrapper
from datahub.emitter.rest_emitter import DatahubRestEmitter
# Imports for metadata model classes
from datahub.metadata.schema_classes import GlossaryTermInfoClass
log = logging.getLogger(__name__)
logging.basicConfig(level=logging.INFO)
term_urn = make_term_urn("rateofreturn")
term_properties_aspect = GlossaryTermInfoClass(
definition="A rate of return (RoR) is the net gain or loss of an investment over a specified time period.",
name="Rate of Return",
termSource="",
)
event: MetadataChangeProposalWrapper = MetadataChangeProposalWrapper(
entityUrn=term_urn,
aspect=term_properties_aspect,
)
# Create rest emitter
rest_emitter = DatahubRestEmitter(gms_server="http://localhost:8080")
rest_emitter.emit(event)
log.info(f"Created term {term_urn}")
Expected Outcome of Creating Terms
You can now see the new term Rate of Return has been created.
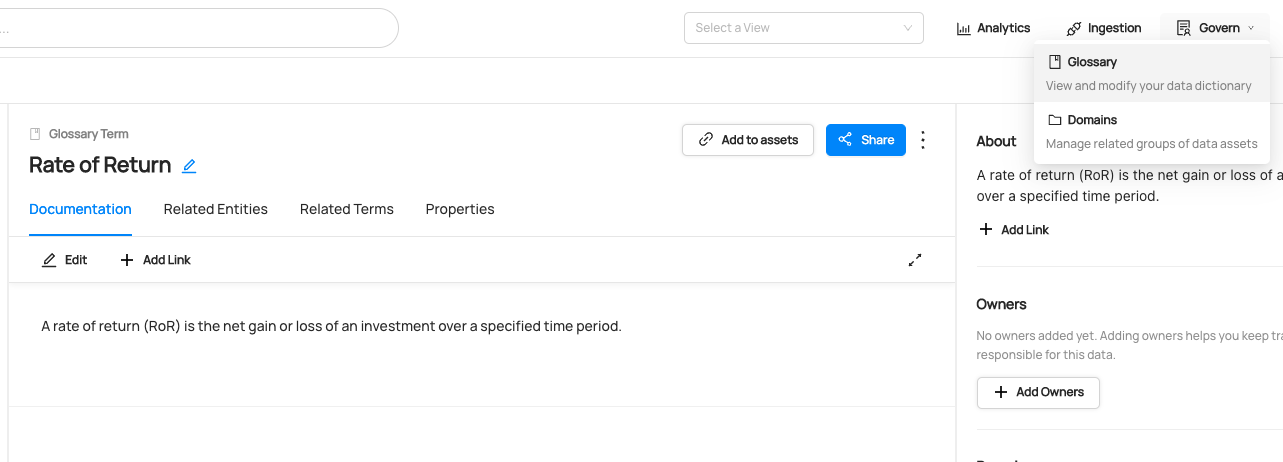
We can also verify this operation by programmatically searching Rate of Return term after running this code using the datahub cli.
datahub get --urn "urn:li:glossaryTerm:rateofreturn" --aspect glossaryTermInfo
{
"glossaryTermInfo": {
"definition": "A rate of return (RoR) is the net gain or loss of an investment over a specified time period.",
"name": "Rate of Return",
"termSource": "INTERNAL"
}
}
Read Terms
- GraphQL
- Curl
- Python
query {
dataset(urn: "urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_created,PROD)") {
glossaryTerms {
terms {
term {
urn
glossaryTermInfo {
name
description
}
}
}
}
}
}
If you see the following response, the operation was successful:
{
"data": {
"dataset": {
"glossaryTerms": {
"terms": [
{
"term": {
"urn": "urn:li:glossaryTerm:CustomerAccount",
"glossaryTermInfo": {
"name": "CustomerAccount",
"description": "account that represents an identified, named collection of balances and cumulative totals used to summarize customer transaction-related activity over a designated period of time"
}
}
}
]
}
}
},
"extensions": {}
}
curl --location --request POST 'http://localhost:8080/api/graphql' \
--header 'Authorization: Bearer <my-access-token>' \
--header 'Content-Type: application/json' \
--data-raw '{ "query": "{dataset(urn: \"urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_created,PROD)\") {glossaryTerms {terms {term {urn glossaryTermInfo { name description } } } } } }", "variables":{}}'
Expected Response:
{"data":{"dataset":{"glossaryTerms":{"terms":[{"term":{"urn":"urn:li:glossaryTerm:CustomerAccount","glossaryTermInfo":{"name":"CustomerAccount","description":"account that represents an identified, named collection of balances and cumulative totals used to summarize customer transaction-related activity over a designated period of time"}}}]}}},"extensions":{}}```
# Inlined from /metadata-ingestion/examples/library/dataset_query_terms.py
from datahub.emitter.mce_builder import make_dataset_urn
# read-modify-write requires access to the DataHubGraph (RestEmitter is not enough)
from datahub.ingestion.graph.client import DatahubClientConfig, DataHubGraph
# Imports for metadata model classes
from datahub.metadata.schema_classes import GlossaryTermsClass
dataset_urn = make_dataset_urn(platform="hive", name="fct_users_created", env="PROD")
gms_endpoint = "http://localhost:8080"
graph = DataHubGraph(DatahubClientConfig(server=gms_endpoint))
# Query multiple aspects from entity
result = graph.get_aspects_for_entity(
entity_urn=dataset_urn,
aspects=["glossaryTerms"],
aspect_types=[GlossaryTermsClass],
)
print(result)
Add Terms
Add Terms to a dataset
The following code shows you how can add terms to a dataset.
In the following code, we add a term Rate of Return to a dataset named fct_users_created.
- GraphQL
- Curl
- Python
mutation addTerms {
addTerms(
input: {
termUrns: ["urn:li:glossaryTerm:rateofreturn"],
resourceUrn: "urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_created,PROD)",
}
)
}
If you see the following response, the operation was successful:
{
"data": {
"addTerms": true
},
"extensions": {}
}
curl --location --request POST 'http://localhost:8080/api/graphql' \
--header 'Authorization: Bearer <my-access-token>' \
--header 'Content-Type: application/json' \
--data-raw '{ "query": "mutation addTerm { addTerms(input: { termUrns: [\"urn:li:glossaryTerm:rateofreturn\"], resourceUrn: \"urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_created,PROD)\" }) }", "variables":{}}'
Expected Response:
{ "data": { "addTerms": true }, "extensions": {} }
# Inlined from /metadata-ingestion/examples/library/dataset_add_term.py
import logging
from typing import Optional
from datahub.emitter.mce_builder import make_dataset_urn, make_term_urn
from datahub.emitter.mcp import MetadataChangeProposalWrapper
# read-modify-write requires access to the DataHubGraph (RestEmitter is not enough)
from datahub.ingestion.graph.client import DatahubClientConfig, DataHubGraph
# Imports for metadata model classes
from datahub.metadata.schema_classes import (
AuditStampClass,
GlossaryTermAssociationClass,
GlossaryTermsClass,
)
log = logging.getLogger(__name__)
logging.basicConfig(level=logging.INFO)
# First we get the current terms
gms_endpoint = "http://localhost:8080"
graph = DataHubGraph(DatahubClientConfig(server=gms_endpoint))
dataset_urn = make_dataset_urn(platform="hive", name="realestate_db.sales", env="PROD")
current_terms: Optional[GlossaryTermsClass] = graph.get_aspect(
entity_urn=dataset_urn, aspect_type=GlossaryTermsClass
)
term_to_add = make_term_urn("Classification.HighlyConfidential")
term_association_to_add = GlossaryTermAssociationClass(urn=term_to_add)
# an audit stamp that basically says we have no idea when these terms were added to this dataset
# change the time value to (time.time() * 1000) if you want to specify the current time of running this code as the time
unknown_audit_stamp = AuditStampClass(time=0, actor="urn:li:corpuser:ingestion")
need_write = False
if current_terms:
if term_to_add not in [x.urn for x in current_terms.terms]:
# terms exist, but this term is not present in the current terms
current_terms.terms.append(term_association_to_add)
need_write = True
else:
# create a brand new terms aspect
current_terms = GlossaryTermsClass(
terms=[term_association_to_add],
auditStamp=unknown_audit_stamp,
)
need_write = True
if need_write:
event: MetadataChangeProposalWrapper = MetadataChangeProposalWrapper(
entityUrn=dataset_urn,
aspect=current_terms,
)
graph.emit(event)
else:
log.info(f"Term {term_to_add} already exists, omitting write")
Add Terms to a Column of a Dataset
- GraphQL
- Curl
- Python
mutation addTerms {
addTerms(
input: {
termUrns: ["urn:li:glossaryTerm:rateofreturn"],
resourceUrn: "urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_created,PROD)",
subResourceType:DATASET_FIELD,
subResource:"user_name"})
}
curl --location --request POST 'http://localhost:8080/api/graphql' \
--header 'Authorization: Bearer <my-access-token>' \
--header 'Content-Type: application/json' \
--data-raw '{ "query": "mutation addTerms { addTerms(input: { termUrns: [\"urn:li:glossaryTerm:rateofreturn\"], resourceUrn: \"urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_created,PROD)\", subResourceType: DATASET_FIELD, subResource: \"user_name\" }) }", "variables":{}}'
Expected Response:
{ "data": { "addTerms": true }, "extensions": {} }
# Inlined from /metadata-ingestion/examples/library/dataset_add_column_term.py
import logging
import time
from datahub.emitter.mce_builder import make_dataset_urn, make_term_urn
from datahub.emitter.mcp import MetadataChangeProposalWrapper
# read-modify-write requires access to the DataHubGraph (RestEmitter is not enough)
from datahub.ingestion.graph.client import DatahubClientConfig, DataHubGraph
# Imports for metadata model classes
from datahub.metadata.schema_classes import (
AuditStampClass,
EditableSchemaFieldInfoClass,
EditableSchemaMetadataClass,
GlossaryTermAssociationClass,
GlossaryTermsClass,
)
log = logging.getLogger(__name__)
logging.basicConfig(level=logging.INFO)
def get_simple_field_path_from_v2_field_path(field_path: str) -> str:
"""A helper function to extract simple . path notation from the v2 field path"""
if not field_path.startswith("[version=2.0]"):
# not a v2, we assume this is a simple path
return field_path
# this is a v2 field path
tokens = [
t for t in field_path.split(".") if not (t.startswith("[") or t.endswith("]"))
]
return ".".join(tokens)
# Inputs -> the column, dataset and the term to set
column = "address.zipcode"
dataset_urn = make_dataset_urn(platform="hive", name="realestate_db.sales", env="PROD")
term_to_add = make_term_urn("Classification.Location")
# First we get the current editable schema metadata
gms_endpoint = "http://localhost:8080"
graph = DataHubGraph(DatahubClientConfig(server=gms_endpoint))
current_editable_schema_metadata = graph.get_aspect(
entity_urn=dataset_urn, aspect_type=EditableSchemaMetadataClass
)
# Some pre-built objects to help all the conditional pathways
now = int(time.time() * 1000) # milliseconds since epoch
current_timestamp = AuditStampClass(time=now, actor="urn:li:corpuser:ingestion")
term_association_to_add = GlossaryTermAssociationClass(urn=term_to_add)
term_aspect_to_set = GlossaryTermsClass(
terms=[term_association_to_add], auditStamp=current_timestamp
)
field_info_to_set = EditableSchemaFieldInfoClass(
fieldPath=column, glossaryTerms=term_aspect_to_set
)
need_write = False
field_match = False
if current_editable_schema_metadata:
for fieldInfo in current_editable_schema_metadata.editableSchemaFieldInfo:
if get_simple_field_path_from_v2_field_path(fieldInfo.fieldPath) == column:
# we have some editable schema metadata for this field
field_match = True
if fieldInfo.glossaryTerms:
if term_to_add not in [x.urn for x in fieldInfo.glossaryTerms.terms]:
# this tag is not present
fieldInfo.glossaryTerms.terms.append(term_association_to_add)
need_write = True
else:
fieldInfo.glossaryTerms = term_aspect_to_set
need_write = True
if not field_match:
# this field isn't present in the editable schema metadata aspect, add it
field_info = field_info_to_set
current_editable_schema_metadata.editableSchemaFieldInfo.append(field_info)
need_write = True
else:
# create a brand new editable schema metadata aspect
current_editable_schema_metadata = EditableSchemaMetadataClass(
editableSchemaFieldInfo=[field_info_to_set],
created=current_timestamp,
)
need_write = True
if need_write:
event: MetadataChangeProposalWrapper = MetadataChangeProposalWrapper(
entityUrn=dataset_urn,
aspect=current_editable_schema_metadata,
)
graph.emit(event)
log.info(f"Term {term_to_add} added to column {column} of dataset {dataset_urn}")
else:
log.info(f"Term {term_to_add} already attached to column {column}, omitting write")
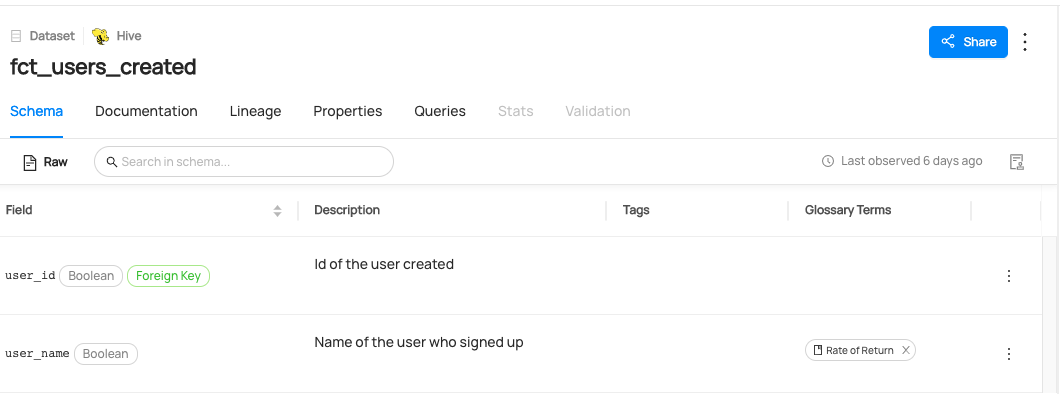
Expected Outcome of Adding Terms
You can now see Rate of Return term has been added to user_name column.
Remove Terms
The following code remove a term from a dataset.
After running this code, Rate of Return term will be removed from a user_name column.
- GraphQL
- Curl
- Python
mutation removeTerm {
removeTerm(
input: {
termUrn: "urn:li:glossaryTerm:rateofreturn",
resourceUrn: "urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_created,PROD)",
subResourceType:DATASET_FIELD,
subResource:"user_name"})
}
Note that you can also remove a term from a dataset if you don't specify subResourceType and subResource.
mutation removeTerm {
removeTerm(
input: {
termUrn: "urn:li:glossaryTerm:rateofreturn",
resourceUrn: "urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_created,PROD)",
})
}
Also note that you can remove terms from multiple entities or subresource using batchRemoveTerms.
mutation batchRemoveTerms {
batchRemoveTerms(
input: {
termUrns: ["urn:li:glossaryTerm:rateofreturn"],
resources: [
{ resourceUrn:"urn:li:dataset:(urn:li:dataPlatform:hdfs,SampleHdfsDataset,PROD)"} ,
{ resourceUrn:"urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_created,PROD)"} ,]
}
)
}
curl --location --request POST 'http://localhost:8080/api/graphql' \
--header 'Authorization: Bearer <my-access-token>' \
--header 'Content-Type: application/json' \
--data-raw '{ "query": "mutation removeTerm { removeTerm(input: { termUrn: \"urn:li:glossaryTerm:rateofreturn\", resourceUrn: \"urn:li:dataset:(urn:li:dataPlatform:hdfs,SampleHdfsDataset,PROD)\" }) }", "variables":{}}'
# Inlined from /metadata-ingestion/examples/library/dataset_remove_term_execute_graphql.py
# read-modify-write requires access to the DataHubGraph (RestEmitter is not enough)
from datahub.ingestion.graph.client import DatahubClientConfig, DataHubGraph
gms_endpoint = "http://localhost:8080"
graph = DataHubGraph(DatahubClientConfig(server=gms_endpoint))
# Query multiple aspects from entity
query = """
mutation batchRemoveTerms {
batchRemoveTerms(
input: {
termUrns: ["urn:li:glossaryTerm:rateofreturn"],
resources: [
{ resourceUrn:"urn:li:dataset:(urn:li:dataPlatform:hdfs,SampleHdfsDataset,PROD)"} ,
{ resourceUrn:"urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_created,PROD)"} ,]
}
)
}
"""
result = graph.execute_graphql(query=query)
print(result)
Expected Outcome of Removing Terms
You can now see Rate of Return term has been removed to user_name column.